☰
CRISP-DM is the de facto standard for developing Data Mining (DM) & Knowledge Discovery (KD) projects and is thus also the most used methodology for these specific projects.
It arose after a group of prominent enterprises (Teradata, SPSS, …) analyzed the problems and obstructions that occurred during DM & KD projects. Subsequently, they proposed a reference guide to develop projects of this nature which then became CRISP-DM (CRoss Industry Standard Process for Data Mining). It is vendor-independent making it applicable to solve any DM related problem.
CRISP-DM defines six phases that need to be carried out during a Data Mining project.
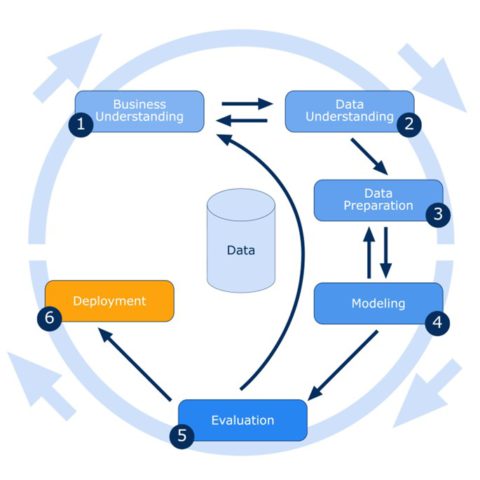
Business understanding: Understanding the project objectives & requirements from a business perspective and converting this knowledge into a DM problem definition and a preliminary plan to achieve these objectives.
Data understanding: discover first insights and detect interesting subsets to form hypotheses for hidden information.
Data preparation: Transform your data into a usable form. Contains all the activities required to construct the final dataset from the initial raw data. If you proceed to the next phase without proper data preparation, your results will never attain the aspired results (garbage in, garbage out).
Modeling: Select and apply various modeling techniques on your data set. During this phase, you usually take a step back to the data preparation phase because some techniques have specific requirements on the form of data.
Evaluation: Evaluate the results of your model thoroughly and review the steps taken to build it to be certain that it properly achieves the business objectives which you defined in phase one.
Deployment: Deploy the model effectively, automate it, plug it into business processes and discuss it with the people that will be using it.
However, the CRISP-DM model still has room for improvement. Other models based on CRISP-DM propose alternative/additional phases like the Automate phase which focuses on generating a tool to help non-experts in the area to perform Data Mining & Knowledge Discovery tasks.
Another example of a phase that is not covered by CRISP-DM is the On-going support phase. It is very important to take this phase into account, as DM & KD projects require a support and maintenance phase. Maintenance can range from creating and maintaining backups of the data used in the project to the regular reconstruction of DM models. This is because the DM models may change whenever new data emerges, which may in turn cause them to be less applicable.
Nonetheless, changes like these (e.g. adding, renaming or eliminating phases) are being considered for the new version (CRISP-DM 2.0).
After comparing this process model to others (especially Software Engineering process models) the conclusion can be made that CRISP-DM does not cover many project management-, organization and quality-related tasks at all or at least not thoroughly enough. In the present day, this has become a must due to how complex projects have become.
Data Mining projects have become more, as they now not only encounter huge streams of data but also require managing and organizing big collaborating teams.
It remains to be seen if a DM engineering process model can be put together that covers the obstacles mentioned above in combination with CRISP-DM in order to adapt it to the most recent DM and KD processes.
Lode Wouters

Vandaag de dag is flexibiliteit belangrijker dan ooit. Het economische landschap wijzigt constant, de gebruikersmarkt is steeds meer veeleisend, de ene crisis lijkt de andere op te volgen, regels en wetten voor bedrijven worden constant aangepast en dan hebben we het nog niet over de krapte op de arbeidsmarkt. De noodzaak voor flexibiliteit Het is […]
Read more

Last tuesday we gathered at the Meadow Club in Antwerp, Belgium, for an exciting afterwork event. This well-deserved break was again a perfect blend of sports, relaxation, and camaraderie 😊 We kicked off with an hour of padel. Our colleagues took to the courts with enthusiasm, showing off their skills and competitive spirit. After all […]
Read more

Technovate 2024, een platform voor innovatie en technologie, bracht dit jaar enkele van de meest vooraanstaande denkers, opinieleiders uit de IT-wereld en visionairs samen om de toekomst van kunstmatige intelligentie (AI) te verkennen. Een van de meest opvallende sprekers op het evenement waren Fiore Fraguelli en zijn collega Simon Uytterhoeven. Ze zijn toonaangevende autoriteiten op […]
Read more